linux零拷贝原理
linux零拷贝原理
本文翻译自:http://www.linuxjournal.com/article/6345
本文解释了Linux的零拷贝作用是什么,为什么它非常有用和在哪些地方可以使用该功能。
到目前为止,几乎每个人都听说过在Linux下的所谓的零拷贝功能,但我经常遇到对这个主题没有完全理解的人。
正因为如此,我决定写一些文章,深入探讨这件事,希望揭开这个有用的功能。
在本文中,我们从用户应用程序的角度看待零拷贝,因此故意省略了gory内核级别的详细信息。
---more
什么是零拷贝
为了更好地理解问题的解决方案,我们首先需要了解问题本身。
让我们看看一个网络服务器通过网络将存储在文件中的数据提供给客户端这个简单过程中涉及的内容,。
以下是一些示例代码:
+-----------------------------------+-----------------------------------+
| 1 | read(file, tmp_buf, len); |
| 2 | write(socket, tmp_buf, len); |
+-----------------------------------+-----------------------------------+
看起来很简单, 你会认为只有两个系统调用并不会有太多的开销。
而然现实中这可能远离真相。
在这两个系统调用之后,数据已经被复制了至少四次,并且几乎执行了同样次数的用户/内核空间的上下文切换。(实际上这个过程要复杂得多,但我想保持简单)。
要更好地了解这些系统调用所涉及的处理过程,请参见图1。
顶部显示上下文切换,底部显示拷贝操作。
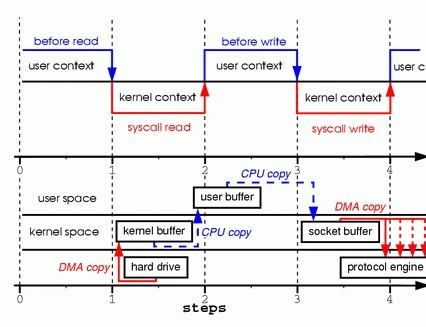
图一: 两个系统调用中的拷贝过程
第一步:read系统调用导致上下文从用户模式切换到内核模式。第一个副本由DMA引擎执行,DMA引擎从磁盘读取文件内容并将它们存储到内核地址空间缓冲区中。
第二步:将数据从内核缓冲区复制到用户缓冲区,并且read系统调用返回。read调用返回导致上下文从内核切换回用户模式。现在数据存储在用户地址空间缓冲区中。
第三步:write系统调用导致上下文从用户模式切换到内核模式。执行第三次复制,以再次将数据放入内核地址空间缓冲区。这个时候,数据被放入一个不同的缓冲区,一个与sockets相关联的缓冲区。
第四步:写系统调用返回,创建我们的第四个上下文切换。独立和异步地,当DMA引擎将数据从内核缓冲区传递到协议引擎时,发生第四次复制。你可能问自己:独立和异步这是什么意思?难道是调用会在数据被传输前返回?
事实上调用返回并不保证数据被传输;它甚至不保证传输的开始。它只是意味着以太网驱动程序在其队列中有空闲描述符,并接受我们的数据进行传输。在我们之前可能有许多数据包在排队。除非驱动器或硬件实现优先级环或队列,否则数据是以先进先出的方式传输的。
(图1中的DMA拷贝说明了最后一个数据拷贝可以被延迟的事实)。
正如你所看到的,很多数据复制操作并不是真正需要的。
可以消除一些复制操作以减少开销并提高性能。
作为驱动程序开发人员,我会和一些具有非常先进功能的硬件打交道。
某些硬件可以完全绕过主存储器,并将数据直接传输到另一个设备。
这个功能减少了一次系统内存的复制操作,是一个很好的功能,但并不是所有的硬件都支持。
还存在必须将来自硬盘的数据针对网络传输重新打包的问题,这引入了一些复杂性。
为了降低开销,我们可以通过消除内核和用户缓冲区之间的一些复制来开始。
mmap
消除复制的一种方法是调用mmap来替代read。 例如:
+-----------------------------------+-----------------------------------+
| 1 | tmp_buf = mmap(file, len); |
| 2 | write(socket, tmp_buf, len); |
+-----------------------------------+-----------------------------------+
为了更好的理解处理过程,请看下图:上下文切换是一样的。
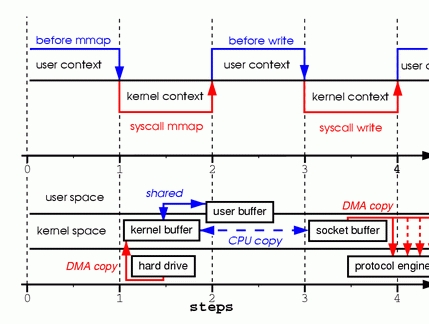
图2. 调用 mmap
第一步:mmap系统调用导致DMA引擎将文件内容复制到内核缓冲区中。然后与用户进程共享缓冲区,而不在内核和用户存储器空间之间执行任何复制。
第二步:write系统调用导致内核将数据从原始内核缓冲区复制到与套接字相关联的内核缓冲区中。
第三步:当DMA引擎将数据从内核套接字缓冲区传递到协议引擎时,发生第三次复制。
通过使用mmap而不是read,我们已经削减了一半的内核必须复制的数据量。当传输大量数据时,这产生相当好的结果。然而,这种改进不是没有代价的;使用mmap + write方法时存在隐藏的缺陷。当内存映射一个文件,然后调用write,而另一个进程截断同一个文件,你会陷入其中之一。您的写系统调用将由总线错误信号SIGBUS中断,因为您执行了错误的存储器访问。该信号的默认行为是杀死进程和转储核心,这不是网络服务器最理想的操作。有两种方法来解决这个问题。
第一种方法是为SIGBUS信号安装一个信号处理程序,然后在处理程序中调用return。通过这样做,写系统调用返回其中断之前写入的字节数,并将errno设置为success。让我指出,这将是一个坏的解决方案,一个解决问题表象而不是问题根本发送原因的方案。因为SIGBUS表明已经发生了非常严重的错误,我不鼓励使用这个解决方案。
第二个解决方案涉及内核中的文件租赁(在Microsoft
Windows中称为"机会锁定")。 这是解决这个问题的正确方法。
通过对文件描述符使用租赁,您可以在特定文件上使用内核租用。
然后,您可以从内核请求读/写租赁。
当另一个进程尝试截断要发送的文件时,内核会向您发送一个实时信号RT_SIGNAL_LEASE信号。
它告诉你内核正在中断你的写入或读取租赁该文件。
您的写调用在程序访问无效地址并被SIGBUS信号终止之前中断。
写调用的返回值是在中断之前写入的字节数,并且errno将设置为success。
这里是一些示例代码,显示如何从内核获取租约:
+-----------------------------------+-----------------------------------+
| 1 | if(fcntl(fd, F_SETSIG, RT_SIG |
| 2 | NAL_LEASE) == -1) { |
| 3 | perror("kernel lease set |
| 4 | signal"); |
| 5 | return -1; |
| 6 | } |
| 7 | /* l_type can be F_RDLCK F_WR |
| 8 | LCK */ |
| 9 | if(fcntl(fd, F_SETLEASE, l_ty |
| | pe)){ |
| | perror("kernel lease set |
| | type"); |
| | return -1; |
| | } |
+-----------------------------------+-----------------------------------+
你应该在mmapping文件之前得到你的租赁,并在你完成后打破租约。
这通过调用具有租用类型F_UNLCK的fcntl F_SETLEASE实现。
[](#Sendfile "Sendfile"){.headerlink}Sendfile
在内核版本2.1中,引入了sendfile系统调用,以简化网络上和两个本地文件之间的数据传输。
sendfile的引入不仅减少了数据复制,还减少了上下文切换。 使用如下:
+-----------------------------------+-----------------------------------+
| 1 | sendfile(socket, file, len); |
+-----------------------------------+-----------------------------------+
为了更好的理解sendfile调用的处理过程请看图3:
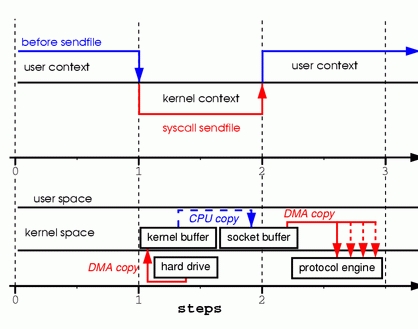
图 3. 使用sendfile替代read,write
第一步:sendfile系统调用导致文件内容被DMA引擎复制到内核缓冲区中。
然后内核将数据复制到与套接字相关联的内核缓冲区中。
第二步:当DMA引擎将数据从内核套接字缓冲区传递到协议引擎时,发生第三次复制。
你可能想知道如果另一个进程截断我们用sendfile系统调用发送的文件会发生什么。
如果我们不注册任何信号处理程序,sendfile调用只是返回它在被中断前传输的字节数并且errno将被设置为成功。
然而,如果我们在调用sendfile之前从内核中获得文件的租约,则行为和返回状态完全相同。
我们还会在sendfile调用返回之前获取RT_SIGNAL_LEASE信号。
到目前为止,我们已经能够避免一些内核复制操作,但是我们仍然有一次内核复制操作。
这也可以避免吗? 当然,这需要硬件的一点帮助。
为了消除内核所做的所有数据复制,我们需要一个支持聚集操作的网络接口。
这仅仅意味着等待传输的数据不需要在连续的内存空间中;
这些数据可以分散在存储器的各个位置。
在内核版本2.4中,修改了套接字缓冲区描述符以适应这些要求-在Linux下称为零拷贝。
这种方法不仅减少了多个上下文切换,还完全消除了处理器的数据复制操作。
对于用户级应用程序没有什么改变,所以代码看起来像这样:
sendfile(socket, file, len);
为了更好的理解sendfile调用的处理过程请看图4:
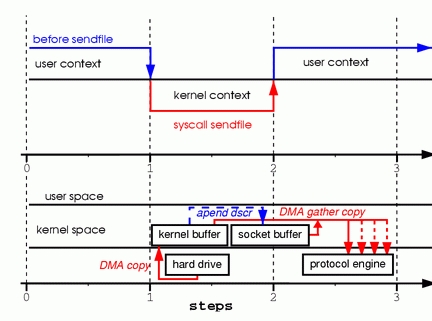
图 4. 支持聚集操作的硬件从内存的多个位置获取数据,消除内存拷贝
第一步:sendfile系统调用导致文件内容被DMA引擎复制到内核缓冲区中。
第二步:没有数据被复制到套接字缓冲区。相反,只有关于数据的位置和长度的信息的描述符附加到套接字缓冲区。
DMA引擎将数据直接从内核缓冲区传递到协议引擎,从而消除最后剩下的一次内存拷贝。
因为数据实际上仍然是从磁盘复制到内存和从内存到电线,有些人可能认为这不是一个真正的零复制。但是,从操作系统的角度来看,这是零拷贝,因为数据不会在内核缓冲区之间来回拷贝。当使用零拷贝时,除了避免拷贝之外,还可以有其他性能优势,例如较少的上下文切换,较少的CPU缓存数据污染和没有CPU计算校验和的操作。
现在我们知道什么是零拷贝,让我们把理论付诸实践并写一些代码。您可以从www.xalien.org/articles/source/sfl-src.tgz下载完整的源代码。要解压缩源代码,请在命令行提示符下键入tar -zxvf sfl-src.tgz。要编译代码并创建随机数据文件data.bin,请运行make。
请看下面的代码:
+-----------------------------------+-----------------------------------+ 除了基本套接字操作所需的常规头文件 +-----------------------------------+-----------------------------------+ 相同的程序既可以作为服务器/发送器也可以作为客户端/接收器。 +-----------------------------------+-----------------------------------+ 我们清除服务器的地址结构信息,并重新分配协议族,服务器的端口和IP地址。 +-----------------------------------+-----------------------------------+ 作为服务器,我们需要为我们的套接字描述符分配一个地址。 +-----------------------------------+-----------------------------------+ 因为我们使用流式套接字,因此必须指定该套接字的连接队列大小。 +-----------------------------------+-----------------------------------+ 系统调用 +-----------------------------------+-----------------------------------+ 一个连接是建立在客户端套接字描述符上的,因此我们可以开始向远程系统传输数据。 +-----------------------------------+-----------------------------------+ 前两个参数是文件描述符。 一般来说, 其中一个实现差异是Linux提供了一个 第二个区别是Linux没有实现向量传输。 Solaris sendfile和HP-UX 在Linux下实现零拷贝远远没有完成,并且很可能在不久的将来发生改变。应添加更多功能。例如, 当前 尽管有一些缺点,但零拷贝
| 1 | /* sfl.c sendfile example pro |
| 2 | gram |
| 3 | Dragan Stancevic < |
| 4 | header name f |
| 5 | unction / variable |
| 6 | ----------------------------- |
| 7 | --------------------*/ |
| 8 | #include
| 9 | * printf, perror */ |
| 10 | #include
| 11 | * open */ |
| 12 | #include
| 13 | * close */ |
| 14 | #include
| | * errno */ |
| | #include
| | * memset */ |
| | #include
| | * socket */ |
| | #include
| | * sockaddr_in */ |
| | #include
| | * sendfile */ |
| | #include
| | * inet_addr */ |
| | #define BUFF_SIZE (10*1024) / |
| | * size of the tmp buffer */ |
+-----------------------------------+-----------------------------------+<sys / socket.h>和<netinet / in.>,我们需要一个sendfile系统调用的原型定义。
这可以在<sys / sendfile.h>服务器标志中找到:
| 1 | /* are we sending or receivin |
| 2 | g / |
| 3 | if(argv[1][0] == 's') is_serv |
| 4 | er++; |
| 5 | / open descriptors */ |
| | sd = socket(PF_INET, SOCK_STR |
| | EAM, 0); |
| | if(is_server) fd = open("data |
| | .bin", O_RDONLY); |
+-----------------------------------+-----------------------------------+
我们需要检查命令行参数数,然后将标志is_server设置为在发送方模式下运行。
我们还打开了INET协议族的流套接字。
作为以服务器模式运行的一部分,我们还需要某种传输到客户端的数据,因此我们打开我们的数据文件。
我们使用系统调用sendfile来传输数据,因此我们不需要读取文件的实际内容并将其存储在我们的程序缓冲区中。
| 1 | /* clear the memory / |
| 2 | memset(&sa, 0, sizeof(struct |
| 3 | sockaddr_in)); |
| 4 | / initialize structure */ |
| 5 | sa.sin_family = PF_INET; |
| 6 | sa.sin_port = htons(1033); |
| | sa.sin_addr.s_addr = inet_add |
| | r(argv[2]); |
+-----------------------------------+-----------------------------------+
服务器的地址作为命令行参数传递。
端口号被硬编码为未分配的端口1033.选择此端口号是因为它高于需要对系统进行根访问的端口范围。
这里是服务器代码的执行分支:
| 1 | if(is_server){ |
| 2 | int client; /* new client |
| 3 | socket */ |
| 4 | printf("Server binding to |
| 5 | [%s]\n", argv[2]); |
| 6 | if(bind(sd, (struct socka |
| 7 | ddr *)&sa, sizeof(sa)) < 0){ |
| 8 | perror("bind"); |
| | exit(errno); |
| | } |
| | } |
+-----------------------------------+-----------------------------------+
这是通过系统调用bind来实现的,它为套接字描述符(sd)分配服务器地址(sa):
| 1 | if(listen(sd,1) < 0){ |
| 2 | perror("listen"); |
| 3 | exit(errno); |
| 4 | } |
+-----------------------------------+-----------------------------------+
我已经将积压队列设置为1,但是常见的是为已建立连接并等待被accept的连接队列设置更高的阈值。
在旧版本的内核中,积压队列用于防止syn洪水攻击。
由于系统调用listen已更改为仅为已建立的连接队列设置长度参数,因此此调用已弃用积压队列功能。
内核参数tcp_max_syn_backlog接管了保护系统免受同步洪水攻击的作用:
| 1 | if((client = accept(sd, NULL, |
| 2 | NULL)) < 0){ |
| 3 | perror("accept"); |
| 4 | exit(errno); |
| | } |
+-----------------------------------+-----------------------------------+accept从等待连接队列上获取第一个请求建立连接的连接对象创建一个新的已经建立连接的套接字。
调用的返回值是新创建的连接的描述符;
该套接字现在已准备好进行read,write或poll/select系统调用:
| 1 | if((cnt = sendfile(client,fd, |
| 2 | &off, BUFF_SIZE)) < 0){ |
| 3 | perror("sendfile"); |
| 4 | exit(errno); |
| 5 | } |
| 6 | printf("Server sent %d bytes. |
| | \n", cnt); |
| | close(client); |
+-----------------------------------+-----------------------------------+
我们是通过sendfile系统调用来实现的,这是在Linux下函数原型:
| 1 | extern ssize_t |
| 2 | sendfile (int __out_fd, int _ |
| 3 | _in_fd, off_t *offset, |
| | size_t __count) __T |
| | HROW; |
+-----------------------------------+-----------------------------------+
第三个参数指向sendfile应该开始发送数据的偏移量。
第四个参数是我们要传输的字节数。
为了使sendfile传输使用零拷贝功能,需要你的网卡支持内存数据聚集操作。
您还需要实现协议所需要的计算校验和功能,例如TCP或UDP。
如果您的NIC(网络接口卡)已过时,并且不支持这些功能,您仍然可以使用sendfile来传输文件。
不同的是内核将在传输缓冲区之前合并缓冲区。移植性问题
sendfile系统调用的一个问题是缺少标准实现,如开放系统调用一样。
Linux,Solaris或HP-UX中的Sendfile实现完全不同。
这对于希望在其网络数据传输代码中使用零拷贝的开发者造成问题。sendfile,它定义了在两个文件描述符(文件到文件)和(文件到套接字)之间传输数据的接口。
另一方面,HP-UX和Solaris只能用于文件到套接字提交。
sendfile具有额外的参数,可消除与将要发送的数据预置标头相关的开销。展望未来
sendfile调用不支持向量传输,并且服务器(如Samba和Apache)必须使用具有TCP_CORK标志设置的多个sendfile调用。这个标志告诉系统更多的数据是在下一个sendfile调用。TCP_CORK也与TCP_NODELAY不兼容,并且当我们要在数据前面添加或后面添加头信息时使用。这是一个通过向量调用来消除当前需要进行多次sendfile调用的完美示例。sendfile中一个相当令人不快的限制是,当传输大于2GB的文件时,不能使用它。这样大小的文件在今天不是不常见的,相当令人失望的是它必须复制所有的数据到数据出口。因为sendfile和mmap方法在这种情况下都不可用,所以sendfile64在未来的内核版本中使用会非常方便。结论
sendfile依然是一个非常有用的功能,我希望你已经发现这篇文章并开始在你的程序中使用它。
如果你对这个主题有更深入的兴趣,请留意我的第二篇文章,题为[Zero Copy
II:Kernel Perspective](),其中我将进一步挖掘零拷贝的内核内部。参考资料