How to Set Locales (i18n) On a Linux or Unix
解决Ubuntu中使用windows文件名乱码问题 – 【人人分享-人人网】
简单解决Ubuntu修改locale的问题-通信,我的最爱-51CTO博客
各种字符集和编码详解 - 快乐就好 - 博客园
十分钟搞清字符集和字符编码 - 文章 - 伯乐在线
unicode wiki
unicode 箭头符号
unicode 装饰符号 0x27xx
locale
如果要设置中文版的字体编码。在每个文件中增加以下内容。
中文版
# vim /etc/profile.d/locale.sh
export LC_CTYPE=zh_CN.UTF-8
export LC_ALL=zh_CN.UTF-8
# vim /etc/locale.conf
LANG=zh_CN.UTF-8
# vim /etc/sysconfig/i18n
LANG=zh_CN.UTF-8
# vim /etc/environment
LANG=zh_CN.UTF-8
LC_ALL=zh_CN.UTF-8
英文版本
# vim /etc/profile.d/locale.sh
export LC_CTYPE=en_US.UTF-8
export LC_ALL=en_US.UTF-8
# vim /etc/locale.conf
LANG=en_US.UTF-8
# vim /etc/sysconfig/i18n
LANG=en_US.UTF-8
# vim /etc/environment
LANG=en_US.UTF-8
LC_ALL=en_US.UTF-8
Ubuntu支持Windows GBK编码
使ubuntu正常显示GB2312、GBK编码文件 思无涯
ubuntu环境设置的字符集utf8,windows默认字符集是GBK,Ubuntu的默认字符集为utf-8,这使 得在用telnet登录远程服务器或查看windows文件时出现乱码。需要将ubuntu环境设置为GBK或GB2312,或设置软件使其正确显示汉 字。下面以GBK字符集为例进行说明:
一、修改Ubuntu默认字符集为GBK
1、首先设置sudo vi /var/lib/locales/supported.d/local
添加一行 zh_CN.GBK GBK
sudo locale-gen生成locale
2、修改ubuntu的字符集
方法一: 修改用户目录下的.profile文件,增加以下内容:
LANGUAGE=”zh_CN:zh:en_US:en”
LANG=zh_CN.GBK
重新登录即可。
这个方法只对该用户有效。
方法二:修改/etc/environment,增加以下内容:
LANGUAGE=”zh_CN:zh:en_US:en”
LANG=zh_CN.GBK
然后重启X即可
这个方法对没有设置LANG及LANGUAGE环境变量的用户有效
Ubuntu 默认采用UTF8编码,可以方便global。但对中文支持,还不细致,即便默认采用中文安装,也并不会自动添加GB*等支持,致使在Ubuntu下访问部分Win文本文件时,出现乱码。
I. 配置系统环境
执行 sudo vi /var/lib/locales/supported.d/zh
加入以下配置参数
zh_CN.GB18030 GB18030 (最新汉字编码字符集,向下兼容GBK,GB2312)
zh_CN.GBK GBK (汉字扩展编码,向下兼容GB2312, 并包含BIG5全部汉字)
zh_CN.GB2312 GB2312 (简化汉字编码字符集, 最近有客户要我们改进GB2312,太看得起我们了,我只能说:"NO!")
zh_CN.GB18031 GB18031 (数字键盘汉字编码输入,面向手持设备,我的Nokia3120从来就是发短信,接听电话,无法和PC通讯,就不用这个了。 maybe用Google Android SDK的大侠们需要这个)
zh_HK.BIG5 BIG5 (繁体)
zh_TW.BIG5 BIG5 (繁体)
然后执行 sudo locale-gen
提示以下信息,成功了
zh_CN.GB18030... done
zh_CN.GBK... done
......
II. 系统环境支持GB*内码了,但用vi, gedit等工具访问文件还会继续乱码,需要针对不同的工具分别配置,使之自己检测支持范围内的编码
e.g. vi
执行 sudo vi /etc/vim/vimrc
加入以下配置参数
let &termencoding=&encoding
set fileencodings=utf-8,gb18030,gbk,gb2312,big5
e.g. gedit
执行 sudo gconf-editor
选择 apps/gedit-2/preferences/encodings
找到 auto_detected 编辑,在Values中分别加入 GB18030,GBK,GB2312,BIG5
编码
man -k unicode
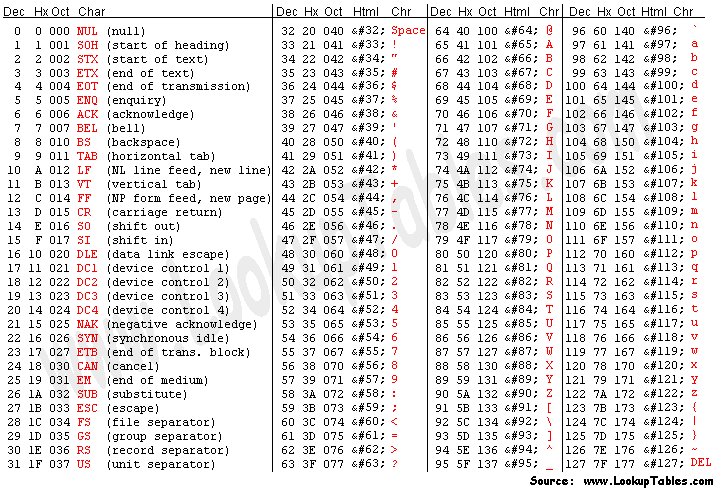
ascii
转义字符串(Escape Sequence)也称字符实体(Character Entity)。在HTML中,定义转义字符串的原因有两个:第一个原因是像“<”和“>”这类符号已经用来表示HTML标签,因此就不能直接当做文本中的符号来使用。为了在HTML文档中使用这些符号,就需要定义它的转义字符串。当解释程序遇到这类字符串时就把它解释为真实的字符。在输入转义字符串时,要严格遵守字母大小写的规则。第二个原因是,有些字符在ASCII字符集中没有定义,因此需要使用转义字符串来表
escape 的用法汇总
escape对除0-255以外的unicode值进行编码时输出%u****格式,
其它情况下escape,encodeURI,encodeURIComponent编码结果相同。
最多使用的应为encodeURIComponent,它是将中文、韩文等特殊字符转换成utf-8格式的url编码,所以如果给后台传递参数需要使用encodeURIComponent时需要后台解码对utf-8支持(form中的编码方式和当前页面编码方式相同)
escape(弃用)不编码字符有69个:*,+,-,.,/,@,_,0-9,a-z,A-Z
encodeURI 不编码字符有82个:!,#,$,&,',(,),*,+,,,-,.,/,:,;,=,?,@,_,~,0-9,a-z,A-Z
encodeURIComponent不编码字符有71个:!,',(,),*,-,.,_,~,0-9,a-z,A-Z
- escape(str) 方法,它用于转义不能用明文正确发送的任何字符。比如,电话号码中的空格将被转换成字符 %20,从而能够在 URL 中传递这些字符
escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如"春节"的返回结果是%u6625%u8282 escape()不对+ - * / @ _ .编码,主要用于汉字编码,现在已经不提倡使用。
encodeURI()是Javascript中真正用来对URL编码的函数。
编码整个url地址,但对特殊含义的符号; / ? : @ & = + $ , #,也不进行编码。对应的解码函数是:decodeURI()。
encodeURIComponent()
能编码; / ? : @ & = + $ , #这些特殊字符。对应的解码函数是decodeURIComponent()。
我想要传递带&符号的网址,所以用encodeURIComponent()
url 编码 [形式为 %20] 字符集可能是utf8 肯能是gbk
[RFC1738 统一资源定位器(URL)](http://man.chinaunix.net/develop/rfc/RFC1738.txt) “`只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。`” 2.2 URL字符编码问题 如果存在下面的情况:八位字节数在US-ASCII字符集中没有相应的可显示字符,或者使 用相应字符会产生不安全因素,或者相应的字符被保留用于特定的URL方案的解释,那 么它们必须被编成代码。 1. 没有相应的可显示字符: URL只能用US-ASCII字符编码集中的可显示字符表示。US-ASCII中没有用到十六进制的 八位字节80-FF,并且00-1F和7F代表了控制字符,这些字符必须进行编码。 2. 不安全: 字符不安全的原因很多。空格字符就是不安全的,因为URL在被转录或者被排版或者被 字处理程序处理后其中重要的空格可能被忽略,而可忽略的空格却有可能被解释了。“<” 和“>”字符也是不安全的,因为它们被用来作为URL在文本中的分隔符;而在有些系统 中用引号“"”来界定URL。“#”字符也是不安全的,因为它在万维网和其他一些系统中 被用来从“片段/锚点”标志符中界定URL,所以它通常都要被编码。字符“%”被用来对 其他字符进行编码,它也是不安全的。其他一些字符,如: "{", "}", "|", "\", "^", "~","[", "]",和"`" ,由于网关和其他传输代理有时会对这些字符进行修改,所以它们也是不安全的。 必须对URL中所有不安全的字符进行编码。例如,URL中的字符“#”即使是在通常不处 理片断或者锚点标志符的系统也需要进行编码,这样如果这个URL被拷贝到使用这些标 志符的系统中,也不必改变URL编码了。 3. 保留: 许多URL方案保留了一些字符并赋予特定的含义:它们出现在URL的特定部位并表示特 定的含义。如果一个字符对应的八位字节在方案中被保留了,那么这个八位字节必须进行 编码。字符";","/", "?", ":", "@", "=" 和 "&"可能被某个方案所保留,除此之外没 有其他的保留字符。 通常情况下一个八位字节被用一个字符表示后或者被编码之后,URL的解释都是一样的。 但这对于保留字符来说就不适用了:对某一特定方案的保留字符进行编码可能会改变URL 的语义。 这样,在URL中只有字母与数字,以及特殊字符“$-_.+!*'(),”和用作保留目的的保留 字符可以不进行编码。 另一方面,不必进行编码的字符(包括字母与数字)如果出现在URL的特定部位,只要 它们不用作保留目的,则可进行编码。 3. html_entity_decode 那么HTML Entity编码具体应该做哪些事情呢?它需要对下面这6个特殊字符进行编码: HTML字符实体(Character Entities) 有些字符在HTML里有特别的含义,比如小于号<就表示HTML Tag的开始,这个小于号是不显示在我们最终看到的网页里的。那如果我们希望在网页中显示一个小于号,该怎么办呢? 这就要说到HTML字符实体(HTML Character Entities)了。 一个字符实体(Character Entity)分成三部分:第一部分是一个&符号,英文叫ampersand;第二部分是实体(Entity)名字或者是#加上实体(Entity)编号;第三部分是一个分号。 比如,要显示小于号,就可以写<或者<。 用实体(Entity)名字的好处是比较好理解,一看lt,大概就猜出是less than的意思,但是其劣势在于并不是所有的浏览器都支持最新的Entity名字。而实体(Entity)编号,各种浏览器都能处理。 注意:Entity是区分大小写的。 如何显示空格 通常情况下,HTML会自动截去多余的空格。不管你加多少空格,都被看做一个空格。比如你在两个字之间加了10个空格,HTML会截去9个空格,只保留一个。为了在网页中增加空格,你可以使用 表示空格。 最常用的字符实体(Character Entities) 显示结果 说明 Entity Name Entity Number 显示一个空格   < 小于 < < > 大于 > > & &符号 & & " 双引号 " " 其他常用的字符实体(Character Entities) 显示结果 说明 Entity Name Entity Number © 版权 © © ® 注册商标 ® ® × 乘号 × × ÷ 除号 ÷ ÷
查看 4E00 - 4EFF 之间的unicode自符
unicode -x 4E00..
#查看 ascii
字符集(Charset):
ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集
字符编码(Character Encoding):
Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三种字符编码方案
How to Set Locales (i18n) On a Linux or Unix
http://www.cyberciti.biz/faq/how-to-set-locales-i18n-on-a-linux-unix/
http://www.linuxfly.org/post/424/
http://blog.csdn.net/lwm_1985/article/details/8509506
添加语言支持
sed -i 's/# zh_CN.UTF-8 UTF-8/zh_CN.UTF-8 UTF-8/' /etc/locale.gen
sed -i 's/# en_US.UTF-8 UTF-8/en_US.UTF-8 UTF-8/' /etc/locale.genlocale-gen和dpkg-reconfigure locales 都是根据 /etc/locale.gen 生成指定的语言
sudo locale-gen en_US.UTF-8 |sudo locale-genDEBIAN_FRONTEND=noninteractive dpkg-reconfigure locales
Generating locales (this might take a while)...
en_US.UTF-8... done
zh_CN.UTF-8... done
Generation complete.
3.update-locale LC_ALL= "zh_CN.UTF-8"
$ cat `/etc/default/locale`
# File generated by update-locale
LANG=zh_CN.UTF-8
LANGUAGE="zh_CN:zh"
4.
export LANG=zh_CN.UTF-8
################################################################################
Configuring Locales
The Easy Way
Install debconf (i.e. run apt-get update then apt-get install debconf, as root)
Run dpkg-reconfigure locales as root
The Hard Way
Edit /etc/locale.gen as root. If /etc/locale.gen does not exist, create it. An example /etc/locale.gen is below.
Run /usr/sbin/locale-gen as root
A sample /etc/locale.gen
This file lists locales that you wish to have built. You can find a list
of valid supported locales at /usr/share/i18n/SUPPORTED. Other
combinations are possible, but may not be well tested. If you change
this file, you need to rerun locale-gen.
#
XXX GENERATED XXX
#
NOTE!!! If you change this file by hand, and want to continue
maintaining manually, remove the above line. Otherwise, use the command
"dpkg-reconfigure locales" to manipulate this file. You can manually
change this file without affecting the use of debconf, however, since it
does read in your changes.
en_US.UTF-8 UTF-8
######
查看所有的locale语言
# locale -a
# locale -a|grep en
■ 查看当前操作系统使用的语言
# echo $LANG
■ 设置系统locale语言为中文环境(永久生效)
vi /etc/sysconfig/i18n
LANG="zh_CN.UTF-8"
■ 设置系统locale语言为英文环境(永久生效)
LANG="en_US.UTF-8"
■ 临时改变系统locale语言(退出本次登录立即失效)
# export LANG=zh_CN.UTF-8
■ 安装中文字体
# yum install fonts-chinese.noarch
■ 指定中文字体路径
vi /etc/X11/fs/config
catalogue = /usr/X11R6/lib/X11/fonts/misc:unscaled,
/usr/X11R6/lib/X11/fonts/75dpi:unscaled,
/usr/X11R6/lib/X11/fonts/100dpi:unscaled,
/usr/X11R6/lib/X11/fonts/Type1,
/usr/share/fonts/default/Type1,
,
/usr/share/fonts/zh_CN/TrueType,
/usr/share/fonts/zh_TW/TrueType
方法2
修改CentOS运行环境的默认语言环境变量值
[root@www ~]# vi /etc/profile
找到export语句,在语句前面加入
LANG=”en_US.UTF-8″
再在export后面追加LANG
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE INPUTRC LANG
保存配置,修改CentOS语言完成。