Golang 文本处理
func reverse(s string) string {
reverseString := []rune(s)
for i, j := 0, len(reverseString)-1; i < len(reverseString)/2; i, j = i+1, j-1 {
reverseString[i], reverseString[j] = reverseString[j], reverseString[i]
}
return string(reverseString)
}
Go文本处理
在go语言中,bytes.Buffer提供了高效的多个bytes连接。
举个栗子:
1)多个[]byte 连接
b1:=[]byte("this is a first string")
b2:=[]byte("this is a second string")
var buffer bytes.Buffer //Buffer是一个实现了读写方法的可变大小的字节缓冲
buffer.Write(b1)
buffer.Write(b2)
b3 :=buffer.Bytes() //得到了b1+b2的结果
2)多个string相连
str1:="this is a first string"
str2:="this is a second string"
buffer.WriteString(str1)
buffer.WriteString(str2)
str3 :=buffer.String() //得到了str1+str2的结果
同学们可能疑惑了,两个string相加不是用str1+str2么?
可以的,但是用bytes.Buffer方式更加的高效,类似于java中的stringBuffer类,
实现了字符串或者字符数组的高效连接,比+拼接方式高效了至少1个数量级。
概览
Go中,字符串string是内置类型,与文本处理相关的内置类型还有符文rune和字节byte。
与C语言类似,大多数关于字符串处理的函数都放在标准库里。Go将大部分字符串处理的函数放在了strings,bytes这两个包里。
因为在字符串和整型间没有隐式类型转换,字符串和其他基本类型的转换的功能主要在标准库strconv中提供。
unicode相关功能在unicode包中提供。
基础数据结构
数组与切片
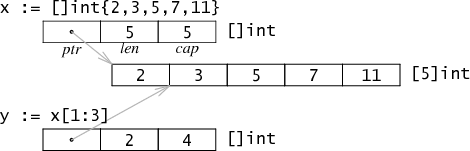
数组Array是固定长度的数据结构,不存放任何额外的信息。通常不直接使用,而是作为切片的底层存储。
切片Slice描述了数组中一个连续的片段。在底层实现中,可以看成一个由三个word组成的结构体,这里word是CPU的字长。这三个字分别是ptr,len,cap,分别代表数组首元素地址,切片的长度,当前切片头位置到底层数组尾部的距离。
字节byte
字节byte实际上就是uint8的别名,只是为了和其他8bit类型相区别才单独起了别名。通常出现的更多的是字节切片[]byte与字节数组[...]byte。
字节可以用单引号扩起的单个字符表示,不过这种字面值和rune的字面值很容易搞混。赋予字节变量一个超出范围的值,如果在编译期能检查出来就会报overflows byte编译错误。
对于字节数组[]byte,实质上可以看做[]uint8,所以字节数组的本体结构定义如下:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
符文rune
符文rune其实是int32的别名,表示一个Unicode的码位。可以与字节和字符串相互转换
符文的字面值是用单引号括起的一个或多个字符,例如a,啊,\a,\141,\x61,\u0061,\U00000061,都是合法的rune literal。其格式定义如下:
rune_lit = "'" ( unicode_value | byte_value ) "'" .
unicode_value = unicode_char | little_u_value | big_u_value | escaped_char .
byte_value = octal_byte_value | hex_byte_value .
octal_byte_value = `\` octal_digit octal_digit octal_digit .
hex_byte_value = `\` "x" hex_digit hex_digit .
little_u_value = `\` "u" hex_digit hex_digit hex_digit hex_digit .
big_u_value = `\` "U" hex_digit hex_digit hex_digit hex_digit
hex_digit hex_digit hex_digit hex_digit .
escaped_char = `\` ( "a" | "b" | "f" | "n" | "r" | "t" | "v" | `\` | "'" | `"` ) .
其中,八进制的数字范围是0~255,Unicode转义字符通常要排除0x10FFFF以上的字符和surrogate字符。
字符串string
字符串通常(但不完全一定)是UTF8编码的文本,由一系列8bit字节组成。字符串是不可变对象,可以空(s=""),但不会是nil。

底层实现上字符串与切片头类似,都带有一个指针,一个长度,但因为字符串一旦创建就不可变所以不需要cap字段,所以字符串其实由两个Word组成。64位机器上就是16个字节。
type StringHeader struct {
Data uintptr
Len int
}
关于string,有这么几点需要注意:
string常量会在编译期分配到只读段,对应数据地址不可写入,相同的string常量不会重复存储。fmt.Sprintf生成的字符串分配在堆上,对应数据地址可修改。- 常量空字符串有数据地址,动态生成的字符串没有设置数据地址
- Golang string和[]byte转换,会将数据复制到堆上,返回数据指向复制的数据
- 动态生成的字符串,即使内容一样,数据也是在不同的空间
- 只有动态生成的string,数据可以被黑科技修改
- string和[]byte通过复制转换,性能损失接近4倍
string与[]byte的转换
常规做法
// []byte to string
s := string(b)
// string to []byte
b := []byte(s)
黑魔法
//return GoString's buffer slice(enable modify string)
func StringToBytes(s string) Bytes {
return *(*Bytes)(unsafe.Pointer(&s))
}
// convert b to string without copy
func BytesToString(b []byte) String {
return *(*String)(unsafe.Pointer(&b))
}
// returns &s[0], which is not allowed in go
func StringPointer(s string) unsafe.Pointer {
p := (*reflect.StringHeader)(unsafe.Pointer(&s))
return unsafe.Pointer(p.Data)
}
// returns &b[0], which is not allowed in go
func BytesPointer(b []byte) unsafe.Pointer {
p := (*reflect.SliceHeader)(unsafe.Pointer(&b))
return unsafe.Pointer(p.Data)
}
string与rune的转换
strings 包提供了很多操作字符串的简单函数,通常一般的字符串操作需求都可以在这个包中找到。
strconv 包提供了基本数据类型和字符串之间的转换。在 Go 中,没有隐式类型转换,一般的类型转换可以这么做:int32(i),将 i (比如为 int 类型)转换为 int32,然而,字符串类型和 int、float、bool 等类型之间的转换却没有这么简单。
进行复杂的文本处理必然离不开正则表达式。regexp 包提供了正则表达式功能,它的语法基于 RE2 ,regexp/syntax 子包进行正则表达式解析。
Go 代码使用 UTF-8 编码(且不能带 BOM),同时标识符支持 Unicode 字符。在标准库 unicode 包及其子包 utf8、utf16中,提供了对 Unicode 相关编码、解码的支持,同时提供了测试 Unicode 码点(Unicode code points)属性的功能。
在开发过程中,可能涉及到字符集的转换,作为补充,本章最后会讲解一个第三方库:mahonia — 纯 Go 语言实现的字符集转换库,以方便需要进行字符集转换的读者。
标准类型与标准库
Go提供了三种
- string
- rune
- []byte