JavaScript与Unicode编码
- 字符集的概念:
- 字符集:就是--编码-->字符的映射
例如:
65-->AASCII字符集:0-255-128---127在中国:
[00000000]最多也不过256个 常用的汉字3000多 全部3w+
[00000000][11111111] 0--65535之间- 用两个字节表示一个汉字:
gb2312(只存了7000左右的汉字 少)-->GBK
- 用两个字节表示一个汉字:
Unicode编码集:
Unicode规定:国 为例 在Unicode有一个独特的号 假设是2976Unicode编码集给世界上大部分的语言每个字符都分配了一个号码
国
[gbk]-->unicode[2976]-->日本-->从Unicode得到 国 字- 把字符转化成对应Unicode对应的编码 以适应不同的计算机平台
- 把字符转化成对应Unicode对应的编码 以适应不同的计算机平台
escape把字符转化成各平台通用的Unicode编码
var str = '中国';
var enc = escape(str);
alert(enc);
alert(unescape(enc));// unescape 对escape转化的Unicode编码 解密
{{ page.title }}
ASCII
ASCII(American Standard Code for Information Interchange) 发音 /ˈæski/,是基于拉丁字母的一套电脑编码系统,标准 ASCII 至今为止使用 7 bits 共定义了 128 个字符,而扩展 ASCII 使用 8 bits 定义了 256 个字符,主要用于显示现代英语和其他西欧语言。
在计算机中,所有的数据在存储和运算时都要使用二进制数表示。一个字节(byte)等于 8 个比特,即二进制位(bit),每一个二进制位有 0 和 1 两种状态,因此一个字节可以对应 256 个不同状态,而每一个状态对应一个符号,从 00000000 到 11111111。例如字母 A 对应十进制为 65,二进制则为 0100 0001。
如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和 ASCII 编码冲突。所以,中国制定了 GB2312 编码,用来把中文编进去。
Unicode
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。它从 0 开始,为每个符号指定一个编号,即码点(code point)。
<!-- 码点 0 的符号就是 null -->
U+0000 = null
目前的 Unicode 字符分为 17 组编排,每组称为平面(Plane),而每平面拥有 65536(即 2^16) 个代码点。然而目前只用了少数平面。Unicode 只是一个字符集,它只规定了字符的二进制代码,UTF-8、UTF-16、UTF-32 都是字符编码,是具体的实现。
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对 Unicode 的可变长度字符编码,它可以使用 1 ~ 4 个字节表示一个符号,根据不同的符号而变化字节长度。
| Unicode 编码(十六进制) | UTF-8 字节流(二进制) |
|---|---|
| 000000-00007F | 0xxxxxxx(128 个字符与 ASCII 完全相同) |
| 000080-0007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx10xxxxxx10xxxxxx10xxxxxx |
UTF-8 和 UTF-16 及 UTF-32 的区别:
| 字符编码 | 是否可变长度 | 最小 bits |
|---|---|---|
| UTF-8 | 是 | 8 |
| UTF-16 | 是 | 16 |
| UTF-32 | 否 | 固定 32 |
UCS-2
UCS-2 编码
在 1991 年 Unicode 团队与 UCS 团队合并字符集之前,UCS 已于 1990 年公布了第一套编码方法 UCS-2,即使用 2 个字节表示已经有码点的字符。UTF-16 编码迟至 1996 年才公布,明确宣布是 UCS-2 的超集,即基本平面字符沿用 UCS-2 编码,辅助平面字符定义了 4 个字节的表示方法。而 JS 是于 1995 年诞生的,因此采用的是 UCS-2 字符编码,如果是 4 个字节的字符,会当作两个双字节的字符处理。
JS 允许采用 \uxxxx 形式表示一个字符,其中 xxxx 表示字符的 Unicode 十六进制码点。这种表示法只限于码点在 \u0000~\uFFFF 之间的字符。超出这个范围的字符,必须用两个双字节的形式表示:
// 例如汉字"𠮷"的码点是 0x20BB7,UTF-16 编码为0xD842 0xDFB7(十进制为55362 57271),需要4个字节储存
// ES5
'a' === '\u0061'; // true
'𠮷' === '\uD842\uDFB7'; // true
'𠮷' === '\u20BB7'; // false
'𠮷'.charCodeAt(0); // 55362
'𠮷'.charCodeAt(1); // 57271
'𠮷'.charCodeAt(1).toString(16); // 'dfb7' 转换为 16 进制
'𠮷'.length === 2; // true
// ES6
'𠮷' === '\u{20BB7}'; // true 可采用大括号 {} 的写法
Array.from('𠮷').length === 1; // true 可得到字符串的正确长度
codePointAt()
ES6 提供的 codePointAt() 能够正确处理 4 个字节储存的字符,返回一个字符的十进制码点:
'𠮷'.codePointAt(0); // 134071
'𠮷'.codePointAt(0).toString(16); // '20bb7'
'𠮷'.codePointAt(1); // 57271 仍然会显示后两个字节对应的十进制字符
for (let myCode of '𠮷') { // for...of循环会正确识别 32 位的 UTF-16 字符
console.log(myCode.codePointAt(0).toString(16)); // '20bb7'
}
String.fromCodePoint()
ES5 提供了 String.fromCharCode(),但不能识别大于0xFFFF的码点。ES6 提供的 String.fromCodePoint() 能正确返回对应字符:
String.fromCharCode(0x20BB7); //"ஷ"
String.fromCodePoint(0x0061) === 'a': // true
String.fromCodePoint(0x20BB7) === '𠮷'; // true
at()
ES5 对字符串对象提供 charAt(),用来返回字符串指定位置的字符。该方法不能识别码点大于 0xFFFF 的字符,而目前 ES6 采用垫片库,可通过 at() 解决此问题:
'a'.charAt(0); // a
'𠮷'.charAt(0); // '�'
'a'.at(0); // a
'𠮷'.at(0); // '𠮷'
normalize()
对于附加符号,如汉语拼音的 Ǒ,可以用以下两种方法表示:
// 一个码点表示一个字符 - 如 Ǒ 的码点是 U+01D1
'Ǒ' === 'u\01D1'; // true
// 两个码点表示一个字符 - 如 Ǒ 可以写成 O(U+004F) + ˇ(U+030C)。
'Ǒ' === '\u004F\u030C'; // true
'\u01D1'==='\u004F\u030C'; // false
因此为了符合 Unicode等价性,ES6 提供了 normalize() 转为同样的序列:
'\u01D1'.normalize() === '\u004F\u030C'.normalize(); // true
URL 编码
只有字母和数字 [0-9a-zA-Z]、一些特殊符号 "$-_.+!*'()," (不包括双引号)、以及某些保留字,才可以不经过编码直接用于 URL。浏览器对于 URL 编码情况各异,因此针对此问题 JS 提供了三种编码方案: escape()、encodeURI() 和 encodeComponentURI()。
encodeURI()
encodeURI() 对 URL 进行完整编码,该方法不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号(: - _ . ! ~ * ' ( ) )进行编码,但是对于 URL 下特殊的 ASCII 标点符号(; / ? : @ & = + $ , #)并不会转义,它输出符号的 UTF-8 形式,并且在每个字节前加上 %。对应解码函数为 decodeURI()。
encodeURI('佘孟都');
// "%E4%BD%98%E5%AD%9F%E9%83%BD"
encodeURI("https://tate-young.github.io/README?hello Tate")
// "https://tate-young.github.io/README?hello%20Tate"
encodeURIComponent()
encodeURIComponent() 用于对 URL 的组成部分进行个别编码,而不用于对整个 URL 进行编码。对于上述 URL 下特殊的 ASCII 标点符号也会进行编码。对应解码函数为 decodeURIComponent()。
encodeURIComponent('佘孟都')
// "%E4%BD%98%E5%AD%9F%E9%83%BD"
encodeURIComponent("https://tate-young.github.io/README?hello Tate")
// "https%3A%2F%2Ftate-young.github.io%2FREADME%3Fhello%20Tate"
Base 64
Base64 是一种最常见的二进制编码方法,用 64 个字符来表示任意二进制数据。编码原理可参考 Base64笔记。

base64 使用场景:
- 电子邮件系统
电子邮件系统一般使用 SMTP(简单邮件传输协议) 将邮件从客户端发往服务器端,邮件客户端使用 POP3(邮局协议) 或 IMAP(因特网信息访问协议) 从服务器端获取邮件。
SMTP 协议一开始是基于纯 ASCII 文本的,对于二进制文件(比如邮件附件中的图像、声音等)的处理并不好,所以后来新增 MIME 标准来编码二进制文件,使其能够通过 SMTP 协议传输。
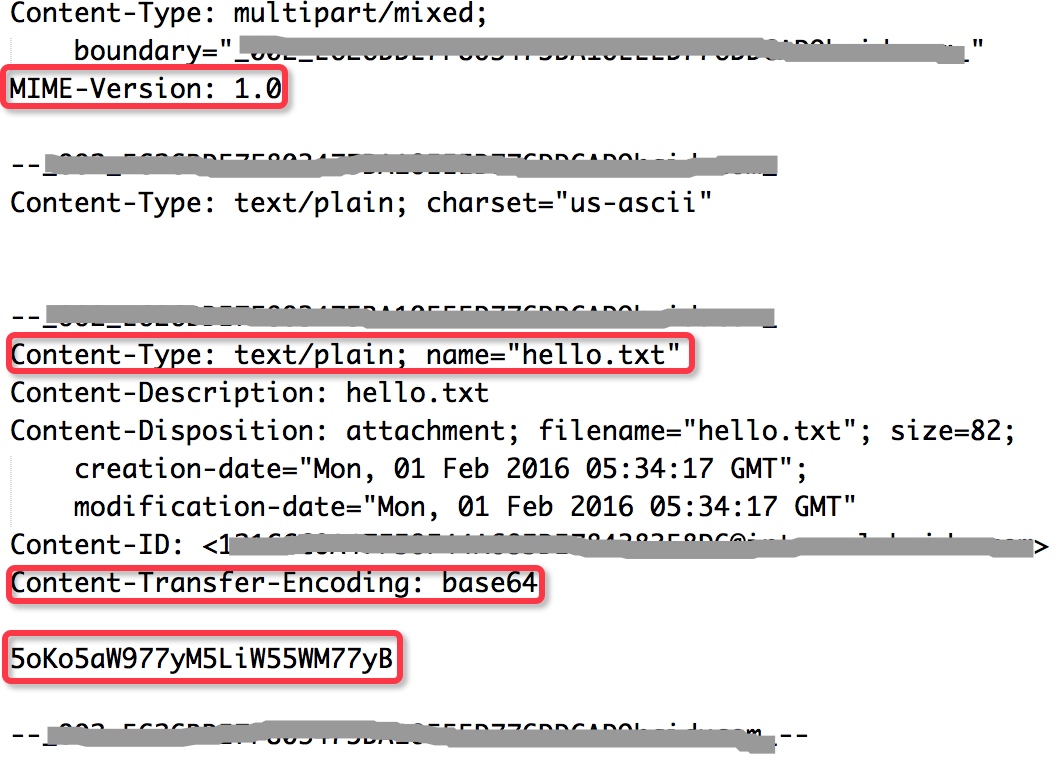
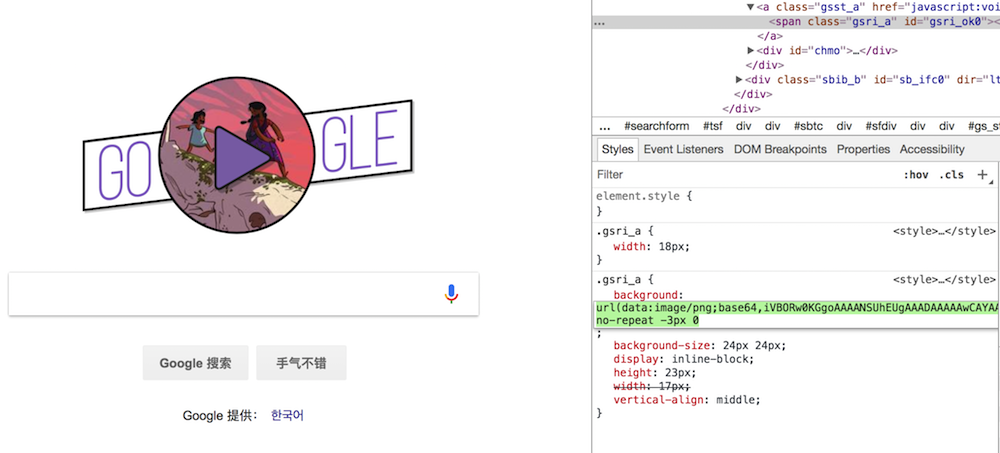
- 图片编码
通过 Base64 将图片编码写入样式内可以避免与服务器交互,避免不必要的下载和加载。其中内容以 Data URLs 形式直接写在 CSS 或嵌入到 HTML 中,如果图片较大,图片的色彩层次比较丰富,则不适合使用这种方式,因为其 Base64 编码后的字符串非常大,影响加载速度。
<!-- Data URLs 形式: url(data:文件类型;编码方式,编码后的文件内容) -->
<img alt="Embedded Image" src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAA..." />
字符引用
在 HTML 或 XML 文档里,如果某些 Unicode 字符在文档的当前编码方式(如ISO-8859-1)中不能直接表示,那么可以通过 字符值引用(NCR) 或者 字符实体引用 两种转义序列来表示这些不能直接编码的字符。
NCR
字符值引用(Numeric Character Reference) 组成结构为 "&#" + Unicode 码点 + ";"
<!-- 「中国」二字分别是 Unicode 字符 U+4E2D 和 U+56FD,十六进制表示的码点数值「4E2D」和「56FD」就是十进制的「20013」和「22269」 -->
中国
中国
NCR 可通过 replace() 替换的方式进行解码:
var regex_num_set = /&#(\d+);/g;
var str = "Tate: 佘孟都"
str = str.replace(regex_num_set, function(match, p1) {
return String.fromCharCode(p1);
});
Character Entity Reference
字符实体引用(Character Entity Reference) 组成结构为 "&" + name + ";"
| 名字 | 字符值引用 | 字符 | 十进制编码 | 含义 |
|---|---|---|---|---|
| quot | " | " | x22 (34) | 双引号 |
| amp | & | & | x26 (38) | & |
| apos | ' | ' | x27 (39) | 撇号 |
| lt | < | < | x3C (60) | 小于号 |
| gt | > | > | x3E (62) | 大于号 |
参考链接
- 字符编码笔记:ASCII,Unicode 和 UTF-8 By 阮一峰
- 关于 URL 编码 By 阮一峰
- Unicode 与 JavaScript 详解 By 阮一峰
- ES6 - 字符串的扩展 By 阮一峰
- Base64 笔记 By 阮一峰
- Base64 编码原理与应用 By youngsterxyf
- stackoverflow - What's the difference between ASCII and Unicode?
- Our Code World - Encode and Decode HTML entities using pure Javascript
- MDN - String.prototype.replace()