目标检测中region proposal的作用
RPN (Region Proposal Network):
Bounding-box: RPN同时也会在feature map上框定这些ROI感兴趣区域的大致位置,即输出Bounding-box。
作者:YJHMITWEB
链接:https://www.zhihu.com/question/265345106/answer/294410307
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
先更正下提问者的描述,yolo本身不含有anchor机制。以下回答适合对目标检测中anchor的作用和机制比较了解的读者阅读。首先我们明确一个定义,当前主流的Object Detection框架分为1 stage和2 stage,而2 stage多出来的这个stage就是Regional Proposal过程,明确这一点后,我们继续讲。Regional Proposal的输出到底是什么?我们首先看一下以Faster R-CNN为代表的2 stage目标检测方法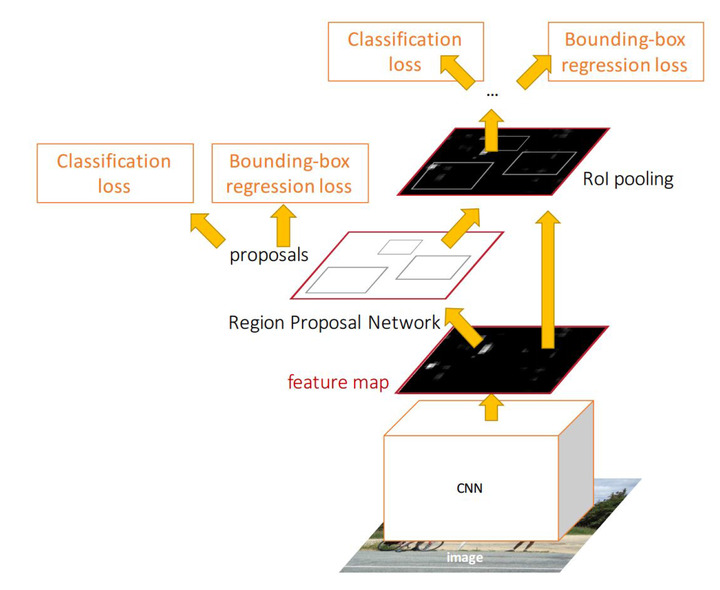 图1可以看到,图中有两个Classification loss和两个Bounding-box regression loss,有什么区别呢?1、Input Image经过CNN特征提取,首先来到Region Proposal网络。由Region Proposal Network输出的Classification,这并不是判定物体在COCO数据集上对应的80类中哪一类,而是输出一个Binary的值p,可以理解为 ,人工设定一个threshold=0.5。RPN网络做的事情就是,如果一个Region的 ,则认为这个Region中可能是80个类别中的某一类,具体是哪一类现在还不清楚。到此为止,Network只需要把这些可能含有物体的区域选取出来就可以了,这些被选取出来的Region又叫做ROI (Region of Interests),即感兴趣的区域。当然了,RPN同时也会在feature map上框定这些ROI感兴趣区域的大致位置,即输出Bounding-box。
图1可以看到,图中有两个Classification loss和两个Bounding-box regression loss,有什么区别呢?1、Input Image经过CNN特征提取,首先来到Region Proposal网络。由Region Proposal Network输出的Classification,这并不是判定物体在COCO数据集上对应的80类中哪一类,而是输出一个Binary的值p,可以理解为 ,人工设定一个threshold=0.5。RPN网络做的事情就是,如果一个Region的 ,则认为这个Region中可能是80个类别中的某一类,具体是哪一类现在还不清楚。到此为止,Network只需要把这些可能含有物体的区域选取出来就可以了,这些被选取出来的Region又叫做ROI (Region of Interests),即感兴趣的区域。当然了,RPN同时也会在feature map上框定这些ROI感兴趣区域的大致位置,即输出Bounding-box。
这里以faster rcnn举例。在faster rcnn里面,anchor(或者说RPN网络)的作用是代替以往rcnn使用的selective search的方法寻找图片里面可能存在物体的区域。
当一张图片输入resnet或者vgg,在最后一层的feature map上面,寻找可能出现物体的位置,
这时候分别以这张feature map的每一个点为中心,在原图上画出9个尺寸不一anchor。然后计算anchor与GT(ground truth) box的iou(重叠率),满足一定iou条件的anchor,便认为是这个anchor包含了某个物体。
目标检测的思想是,首先在图片中寻找“可能存在物体的位置(regions)”,然后再判断“这个位置里面的物体是什么东西”,所以region proposal就参与了判断物体可能存在位置的过程。
region proposal是让模型学会去看哪里有物体,GT box就是给它进行参考,告诉它是不是看错了,该往哪些地方看才对。
建议详细阅读这个领域一系列的论文,从rcnn、sppnet、frcnn、faster rcnn到ssd、yolo,整条线看下来就能大概明白目标检测的“套路”。