PascalVoc
Pascal Voc数据集详细分析 - 持久决心的博客 - CSDN博客
PASCAL VOC 2012 数据集详解 - wenxueliu的博客 - CSDN博客
前言
做深度学习目标检测方面的同学怎么都会接触到PASCAL VOC这个数据集。也许很少用到整个数据集,但是一般都会按照它的格式准备自己的数据集。所以这里就来详细的记录一下PASCAL VOC的格式,包括目录构成以及各个文件夹的内容格式,方便以后自己按照VOC的标准格式制作自己的数据集。
正文
相关网址
Pascal VOC网址:http://host.robots.ox.ac.uk/pascal/VOC/
查看各位大牛算法的排名的Leaderboards:http://host.robots.ox.ac.uk:8080/leaderboard/main_bootstrap.php
训练/验证数据集下载(2G):host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
官方说明:The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Development Kit
VOCdevkit文件夹
数据集下载后解压得到一个名为VOCdevkit的文件夹,该文件夹结构如下:
.
└── VOCdevkit #根目录
└── VOC2012 #不同年份的数据集,这里只下载了2012的,还有2007等其它年份的
├── [Annotations] #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── [ImageSets] #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action #Action文件夹:存放的是人体动作,(例如running、jumping等等,这也是VOC challenge的一部分)
│ ├── Layout #Layout文件夹:存放的是人体部位的数据 (人的head、hand、feet等等,这也是VOC challenge的一部分)
│ ├── [Main] #Main存放的是同我们目标检测项目 相关的图像物体识别数据,文件夹下为txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ └── Segmentation #Segmentation:存放可用于分割的数据
├── [JPEGImages] #存放源图片,同Annotations中的xml文件一一对应。
├── SegmentationClass #存放的是图片,语义分割相关
└── SegmentationObject #存放的是图片,实例分割相关
这里大概介绍一下各个文件夹的内容,更细节的介绍将在后文给出:
- Annotation 文件夹存放的是xml文件,该文件是对图片的解释,每张图片都对于一个同名的xml文件。
- ImageSets 文件夹存放的是txt文件,这些txt将数据集的图片分成了各种集合。如Main下的train.txt中记录的是用于训练的图片集合
- JPEGImages文件夹存放的是数据集的原图片
- SegmentationClass以及SegmentationObject文件夹存放的都是图片,且都是图像分割结果图(楼主没用过,所以不清楚)
Annotation文件夹
Annotation文件夹的内容如下:
其中xml主要介绍了对应图片的基本信息,如来自那个文件夹、文件名、来源、图像尺寸以及图像中包含哪些目标以及目标的信息等等,内容如下:
<annotation>
<folder>VOC2012</folder> #表明图片来源
<filename>2007_000027.jpg</filename> #图片名称
<source> #图片来源相关信息
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> #图像尺寸
<width>486</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented> #是否用于分割
<object>
<name>dog</name> # 物体类别
<pose>Left</pose> # 拍摄角度:front, rear, left, right, unspecified
<truncated>1</truncated> # 目标是否被截断(比如在图片之外),或者被遮挡(超过15%)
<difficult>0</difficult> # 检测难易程度,这个主要是根据目标的大小,光照变化,图片质量来判断
<bndbox>
<xmin>48</xmin>
<ymin>240</ymin>
<xmax>195</xmax>
<ymax>371</ymax>
</bndbox>
</object>
<object> #包含的物体
<name>person</name> #物体类别
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox> #物体的bbox
<xmin>174</xmin>
<ymin>101</ymin>
<xmax>349</xmax>
<ymax>351</ymax>
</bndbox>
<part> #物体的头
<name>head</name>
<bndbox>
<xmin>169</xmin>
<ymin>104</ymin>
<xmax>209</xmax>
<ymax>146</ymax>
</bndbox>
</part>
<part> #物体的手
<name>hand</name>
<bndbox>
<xmin>278</xmin>
<ymin>210</ymin>
<xmax>297</xmax>
<ymax>233</ymax>
</bndbox>
</part>
<part>
<name>foot</name>
<bndbox>
<xmin>273</xmin>
<ymin>333</ymin>
<xmax>297</xmax>
<ymax>354</ymax>
</bndbox>
</part>
<part>
<name>foot</name>
<bndbox>
<xmin>319</xmin>
<ymin>307</ymin>
<xmax>340</xmax>
<ymax>326</ymax>
</bndbox>
</part>
</object>
</annotation>
ImageSets/Main/ 文件夹以 , {class}_trainval.txt {class}_val.txt 的格式命名。 train.txt val.txt 例外
car_train.txt
car_trainval.txt
car_val.txt
dog_train.txt
dog_trainval.txt
dog_val.txt
horse_train.txt
horse_trainval.txt
horse_val.txt
motorbike_train.txt
motorbike_trainval.txt
motorbike_val.txt
person_train.txt
person_trainval.txt
person_val.txt
train.txt
trainval.txt
val.txt
{class}_train.txt 保存类别为 class 的训练集的所有索引,每一个 class 的 train 数据都有 5717 个。
{class}_val.txt 保存类别为 class 的验证集的所有索引,每一个 class 的val数据都有 5823 个
{class}_trainval.txt 保存类别为 class 的训练验证集的所有索引,每一个 class 的val数据都有11540 个
每个文件包含内容为
2011_003194 -1
2011_003216 -1
2011_003223 -1
2011_003230 1
2011_003236 1
2011_003238 1
2011_003246 1
2011_003247 0
2011_003253 -1
2011_003255 1
2011_003259 1
2011_003274 -1
2011_003276 -1
注:1代表正样本,-1代表负样本。
-1:Negative: The image contains no objects of the class of interest. A classifier should give a negative' output.
负片:图像不包含感兴趣类别的对象。分类器应给出“负”输出。
1:Positive: The image contains at least one object of the class of interest. A classifier should give apositive' output.
正片:图像包含至少一个感兴趣类别的对象。分类器应给出“正”输出。
0:Difficult'': The image contains only objects of the class of interest marked as `difficult'.
困难'':图像仅包含标记为``困难''的感兴趣类别的对象。
困难''标签表示所有感兴趣类别的对象都已标注为困难'',例如清晰可见但在不大量使用上下文的情况下很难识别的对象。目前,评估忽略了此类图像,对精度/召回曲线或AP测量没有任何贡献。根据提交的结果,最终评估可能包括单独的结果,包括此类``困难''图像。参与者可以自由地从训练中忽略这些图像,也可以包括正面或负面的例子。
VOC2012/ImageSets/Main/train.txt 保存了所有训练集的文件名,从 VOC2012/JPEGImages/ 找到文件名对应的图片文件。VOC2012/Annotations/ 找到文件名对应的标签文件
Main/train.txt 文件不包含其他额外的样本信息,文件的内容为
2008_000008
2008_000015
2008_000019
2008_000023
VOC2012/ImageSets/Main/val.txt 保存了所有验证集的文件名,从 VOC2012/JPEGImages/ 找到文件名对应的图片文件。VOC2012/Annotations/ 找到文件名对应的标签文件
读取 JPEGImages 和 Annotation 文件转换为 tf 的 Example 对象,写入 {train|test}{index}_of{num_shard} 文件。每个文件写的 Example 的数量为 total_size/num_shard。(不同数据集可以适当调节 num_shard 来控制每个输出文件的大小)
ImageSets文件夹
ImageSets包含如下四个子文件夹:
各个文件夹中存放的是各种用途的TXT文件。例如在Main文件夹下有名为aeroplane_train.txt的文件,顾名思义是用于飞机类别的训练数据。该txt的具体内容如下,其中±1应该表示的是正负样本的含义(没有具体研究):

2008_000008 -1
2008_000015 -1
2008_000019 -1
2008_000023 -1
2008_000028 -1
2008_000033 1
2008_000036 -1
2008_000037 1
2008_000041 -1
2008_000045 -1
其中包含的train.txt以及trainval.txt等文件内容与上面类似。不过博主发现train.txt和trainval.txt内容中光有图片的名字,末尾没有标注正负1.
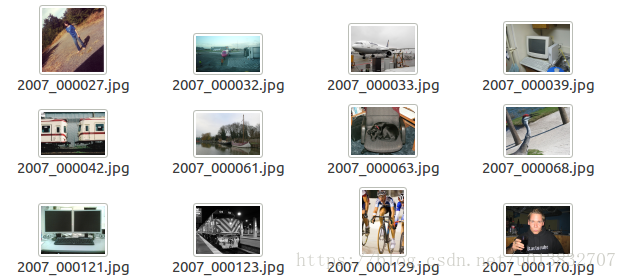
###JEPGImages文件夹
该文件夹存放的是数据集的所有源图片,内容如下:
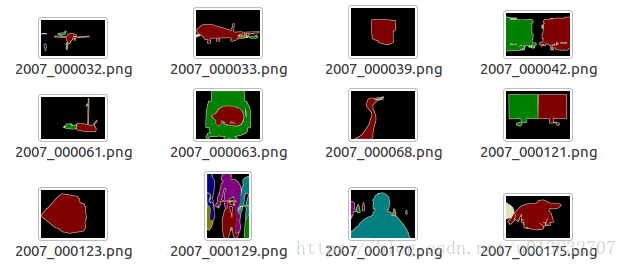
SegmentationClass文件夹
语义分割相关:
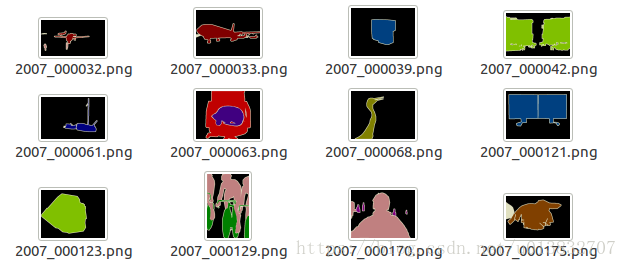
SegmentationObject文件夹
实例分割相关: